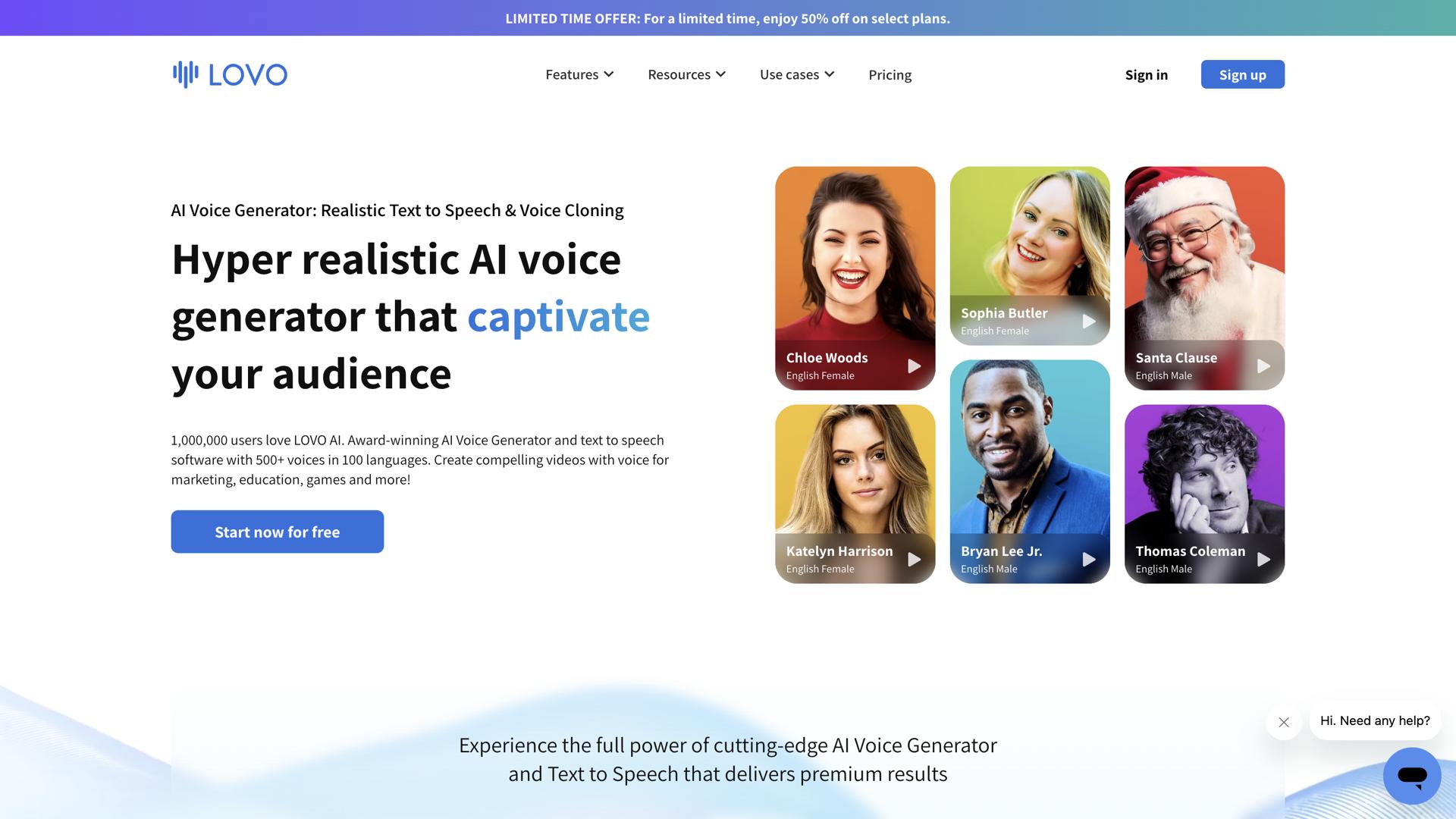
什么是 TensorFlow Voice?
TensorFlow Voice是由谷歌开发的一款强大的语音识别软件。它帮助各层次的开发者快速且准确地将音频记录转换为文本。TensorFlow Voice利用最新的人工智能技术提供直观、用户友好的体验。凭借其先进的机器学习算法,它可以准确识别不同的声音和口音,使开发者能够处理来自广泛来源的音频记录。该软件还为用户提供对转换过程更多的控制,允许他们调整语音识别的准确性和速度。对于那些希望使用语音数据构建应用程序的人来说,TensorFlow Voice是一个不可或缺的工具。其行业领先的准确性、可扩展性和灵活性使其成为需要快速准确地将音频记录转换为文本的开发者的完美选择。借助TensorFlow Voice,开发者可以迅速创建使用语音数据的应用程序,从而提供更好的用户体验并解锁新的可能性。请分享您的体验并对社区做出贡献!现在就来评价吧!
主要功能
- 利用TensorFlow Voice的AI技术将音频录音转化为准确文本
- 调整语音识别的准确率和速度以获得定制化的结果
- 利用语音数据创建应用程序以提升用户体验
付费策略
联系定价